Tencent-HQ-BIM-Data-Pipeline-with-AWS
Tencent Headquarters BIM Data Pipeline Using Apache Airflow, AWS Services, and Autodesk Platform Services
This project delivers an end-to-end data pipeline solution designed to process BIM (Building Information Modeling) data from the Revit model of Tencent Global Headquarters in Shenzhen. Developed during the design and construction phases, the pipeline efficiently handles unitized curtain wall metadata to support data-driven decision-making.
Integrating upstream metadata extraction and pre-processing from Autodesk BIM 360 and downstream cloud-based storage, partitioning, schema cataloging, and analytics using AWS services, the pipeline leverages Apache Airflow, Autodesk Platform Services (APS) APIs, AWS CloudFormation, Amazon S3, AWS Glue, and Amazon Redshift. It enables automated, scalable workflows for data extraction, transformation, and storage.
Tailored for design teams, technical consultants, and Tencent clients, the solution supports precise construction detail modifications, cost optimization, and regulatory compliance with standards for energy consumption and fire protection. Its modular and iterative BIM data processing approach adapts to evolving design requirements while preserving architectural integrity.
Table of Contents
- Pipeline Workflow
- Architecture
- Technologies Used
- Prerequisites
- System Setup
- Project Context and Data Source
Pipeline Workflow
- Infrastructure Deployment:
- Define and provision AWS resources using AWS CloudFormation templates to ensure a scalable foundation for the pipeline.
- Data Extraction:
- Extract BIM data through APS API, targeting metadata such as curtain wall attributes.
- Data Transformation:
- Engineer features (e.g., operable area, embodied carbon, and facade costs) using Python libraries like Pandas and NumPy.
- Data Validation and Loading:
- Validate and save transformed data locally as CSV files before uploading to Amazon S3.
- ETL in AWS Glue:
- Apply additional transformations in Glue, including timestamp-based partitioning and schema validation for efficient querying.
- Amazon Redshift Spectrum Integration:
- Query S3-stored data using Redshift Spectrum via Glue Data Catalog. This approach aligns with AWS’s data lake architecture, enabling analytics and insights without duplicating data storage.
Architecture
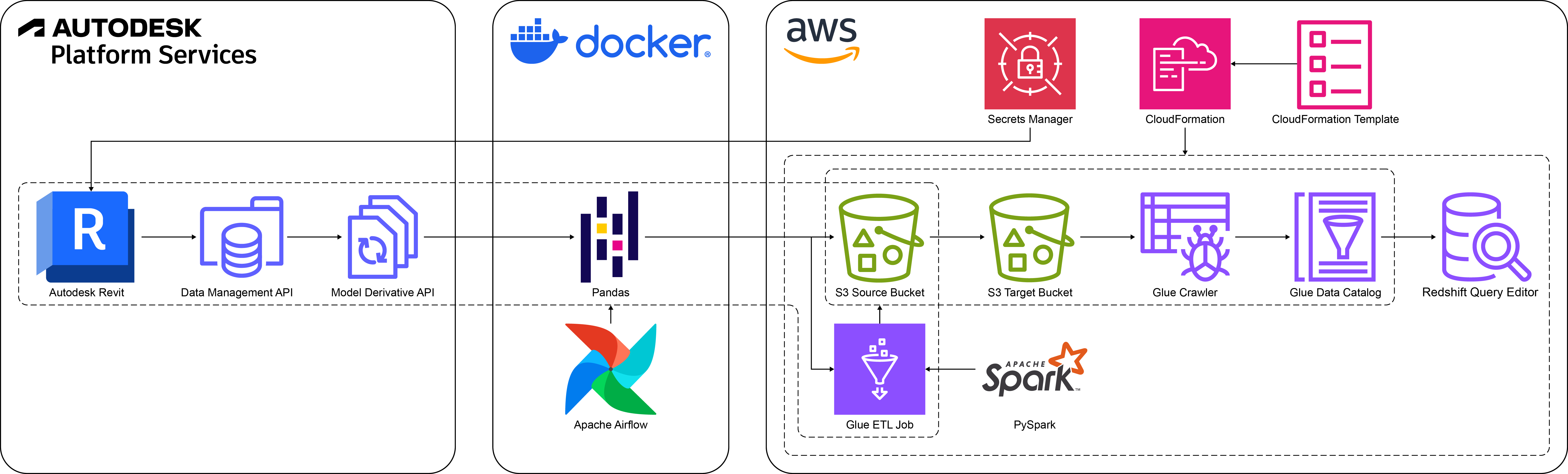
- Autodesk Revit Model in BIM 360: Data source hosted on a cloud-based construction management platform.
- APS Data Management API: Manages authentication and retrieves access to Revit files stored in BIM 360.
- APS Model Derivative API: Extracts metadata from 3D models in Revit for downstream processing.
- Apache Airflow: Orchestrates ETL processes and manages task dependencies.
- AWS CloudFormation: Automates provisioning of AWS resources for the pipeline.
- AWS Secrets Manager: Securely stores APS client credentials for authentication with APS APIs without hardcoding.
- Amazon S3: Provides scalable storage for raw data, partitioned data, and PySpark-based Glue job scripts.
- AWS Glue: Facilitates ETL jobs, data schema crawling, and metadata table cataloging.
- Amazon Redshift: Acts as the data warehouse for analytics, interactive queries, and built-in visualization.
Technologies Used
- Programming Languages: Python (Pandas, NumPy, PySpark, Requests)
- ETL Orchestration: Apache Airflow
- Cloud Services: AWS CloudFormation, AWS Secrets Manager, Amazon S3, AWS Glue, Amazon Redshift
- APIs: APS (Data Management API, Model Derivative API), AWS SDK for Python (Boto3)
Prerequisites
- Revit Model: A Revit model hosted and managed in BIM 360.
- APS API Credentials: Obtain required credentials (client ID and client secret) for API access.
- AWS Account: Ensure sufficient permissions for S3, Glue, and Redshift services.
- Docker Installation: Install Docker to run Airflow in a containerized environment.
- Python Version: Use Python 3.9 or higher for running the scripts and configurations.
System Setup
- Clone the repository.
- Register your app in the Autodesk Developer Portal to obtain APS client credentials:
- Create an app and note the client ID and client secret.
- Ensure your Revit model is accessible in BIM 360.
- Configure AWS environment:
- Create an IAM user with
AdministratorAccesspolicy. - Store APS client credentials and AWS access keys securely in AWS Secrets Manager.
- Update
conf/config.confwith the following values:- Names of secrets for APS client credentials and AWS access keys.
- Project ID, Item ID, and Model View name of your model in BIM 360.
- S3 bucket name matching the
aws-resource-stack-deploy.yamltemplate. - Glue job name customized to your specific requirements.
- Create an IAM user with
- Deploy AWS Resources Using CloudFormation:
- Locate the
aws-resource-stack-deploy.yamltemplate in the root directory. - Open the template and update the
Parameterssection with custom values tailored to your project. - Create the stack using Amazon CloudFormation to provision AWS resources, including configurations of the following:
- S3Bucket
- S3BucketPolicy
- GlueDatabase
- GlueJob
- GlueServiceRole
- RedshiftServerlessNamespace
- RedshiftServerlessWorkgroup
- RedshiftServiceRole
- Locate the
- Set up Docker for Apache Airflow:
- Locate the
docker-compose.yamltemplate in the root directory. - Verify that the following structure aligns with the Airflow scripts and resources mapped to the container’s file system:
└── root ├── airflow.env ├── aws_glue_job_script │ └── partition_job.py ├── config │ └── config.conf ├── dags │ └── bim_aws_dag.py ├── data │ └── output ├── etls │ ├── aws_etl.py │ ├── bim_etl.py │ └── __init__.py ├── pipelines │ ├── aws_pipeline.py │ ├── bim_pipeline.py │ └── __init__.py ├── utils │ ├── constants.py │ └── __init__.py ├── docker-compose.yaml └── requirements.txt - The following auxiliary files and folders are included in the repository for additional context but are not mapped to the container’s file system:
README.md(documentation)assets(images used inREADME.md)data/output/prefix_yyyyMMdd_suffix.csv(example CSV output for reference)aws-resource-stack-deploy.yaml(CloudFormation template for optional AWS setup)amazon_redshift_queries/latest_partition_view.ipynb(example Redshift query notebook demonstrating late-binding views for partitioned BIM data)
- Locate the
- Configure Airflow environment:
- Update
airflow.envwith the following values to configure Airflow email notifications:AIRFLOW__SMTP__SMTP_HOST: Host server address used by Airflow when sending out email notifications via SMTP.AIRFLOW__SMTP__SMTP_USER: Username to authenticate when connecting to SMTP server.AIRFLOW__SMTP__SMTP_PASSWORD: Password to authenticate when connecting to SMTP server.AIRFLOW__SMTP__SMTP_MAIL_FROM: Default “from” email address used when Airflow sends email notifications.
- Update
- Start Docker container for Apache Airflow.
docker compose up - Launch the Airflow web UI.
open http://localhost:8080 - Deploy the Airflow DAG and start the pipeline:
- Run the following command to trigger the DAG:
docker compose exec airflow-webserver airflow dags trigger bim_aws_dag - Alternatively, trigger the DAG manually from the Airflow web UI.
- Run the following command to trigger the DAG:
- After this pipeline is executed, the S3 bucket should have the following structure:
└── s3-bucket-name ├── aws_glue_assets/ │ ├── scripts/ │ │ └── prefix_partition_job.py │ └── temporary/ ├── partitioned/ │ ├── timestamp=yyyy-MM-ddTHH:mm:ss.SSSZ/ │ └── ... └── raw/ ├── prefix_yyyyMMdd_suffix.csv └── ...
Project Context and Data Source
To provide context for the data pipeline, here are some architectural renderings, facade diagrams, and construction details from the Tencent Global Headquarters project. These visuals highlight the unitized curtain wall system, a key focus of the BIM data used in this pipeline.
Architectural Renderings

Facade Diagrams
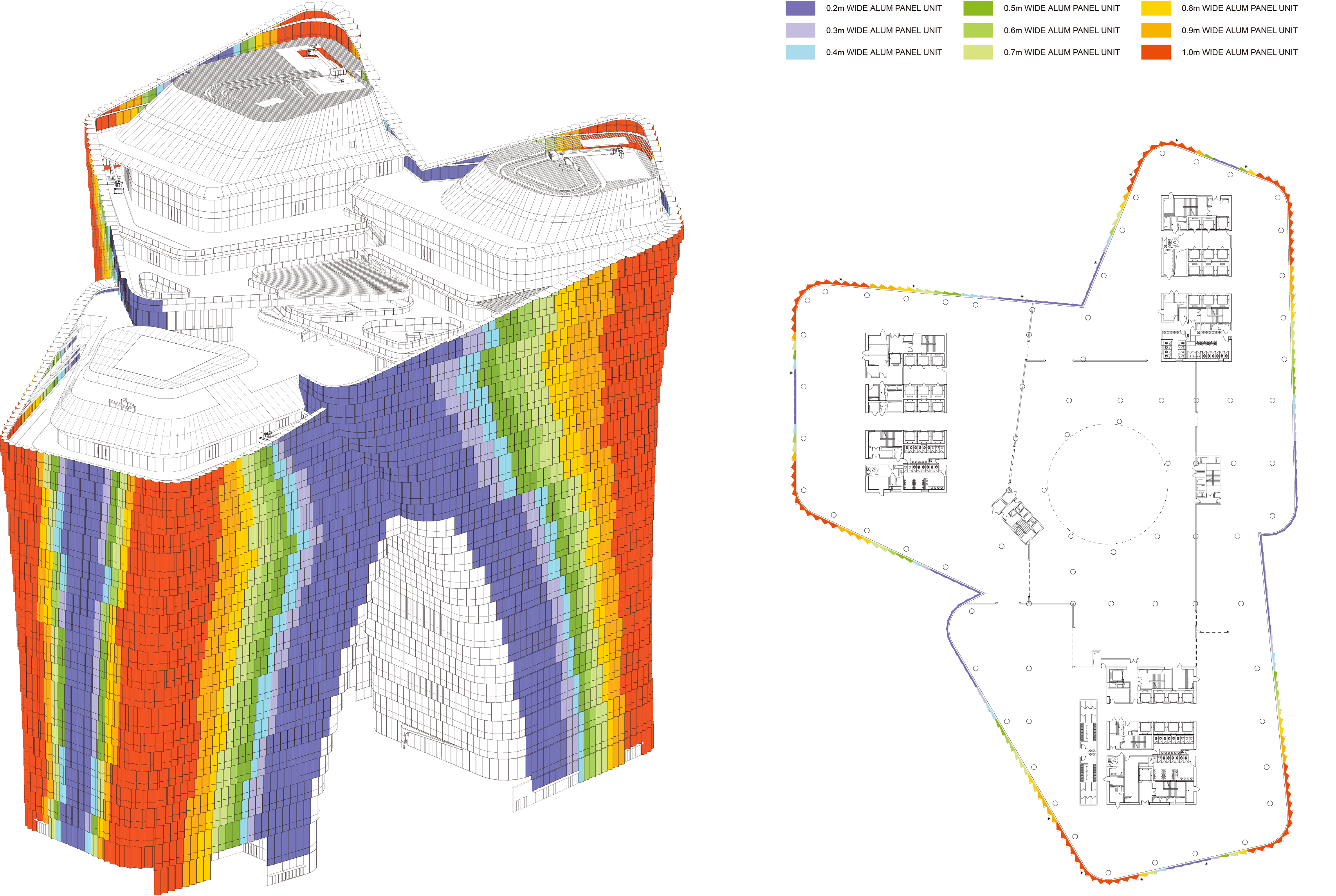
Construction Details of Unitized Curtain Wall System
